
01 · The Problem in a Nutshell
The technology behind typical enterprise AI answer engine implementation is called Retrieval Augmented Generation, or RAG, and it works well for simple tasks: finding a clause in a contract, summarising a study report, pulling out key points from a regulatory submission. Where it falls apart is with complex questions that require precise answers.
Consider what happens when a brand director asks: “Which content themes are driving the highest HCP engagement for our respiratory portfolio across digital channels in Northern Europe?” Answering that properly requires the system to understand what content exists, how it has been classified, which HCPs saw it, through which channels, in which markets, over what time period, and what happened next. That information lives in at least six different systems: the MLR platform for content approvals, your CRM for field activity, your marketing automation platform for email engagement, your analytics tools for web behaviour, your brand plan for strategic context, and your finance system for spend data. No amount of clever document searching will connect those dots, because the connections between those systems do not exist as searchable text. They exist as relationships, and relationships require structure.
This is where most enterprise AI implementations are stuck right now. The finding-stuff part works. The writing-an-answer part works. What needs sorting out is the bit in the middle: getting the system to actually understand how your content, your customers, your channels, and your commercial outcomes relate to each other, and whether any of that information is still true today.
In Gartner’s 2025 Hype Cycle for Artificial Intelligence, generative AI has slid into the “Trough of Disillusionment,” Gartner’s term for the stage where inflated expectations give way to the realities of integration, governance, and scaling. Fewer than 30% of CEOs are satisfied with returns on their GenAI investments. The data architecture gap is one of several factors driving this disillusionment, but it is the one most directly addressable, and the one where structured foundations have the clearest impact on outcomes.
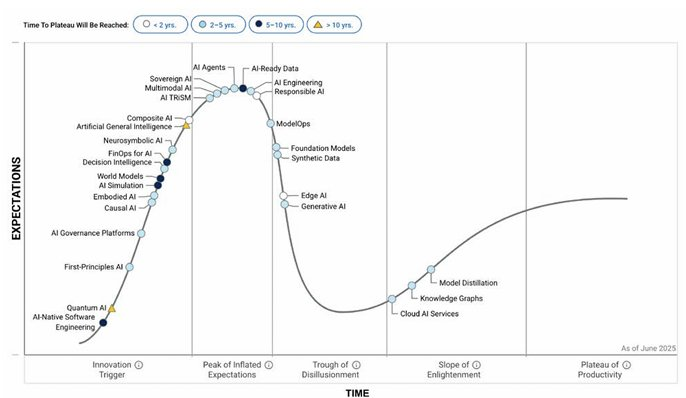
Source: Gartner (2025). Hype Cycle for Artificial Intelligence. Khandabattu, H. and Tamersoy, B., 11 June 2025.
Better models will not necessarily fix this. The problem is structural, and the solution is giving your AI the context it needs to actually reason about your business. The rest of this paper explains how.
02 · The Problem Explained: Why RAG Alone Is Not Enough
To understand why some AI implementations underperform in pharma, it helps to understand how they actually work, because once you see the mechanics, the limitations become obvious.
How RAG Works
A standard RAG system does three things. First, it takes your question and converts it into a mathematical representation. Second, it searches a database of pre-processed document chunks to find the ones whose mathematical representations are most similar to your question. Third, it feeds those chunks to a large language model along with your original question, so the model can generate a response grounded in your actual data rather than its general training.
This is a genuine improvement over using a language model on its own. The model is no longer reasoning solely from its training data, which is generic. It is working with real information from your organisation. So far, so good.
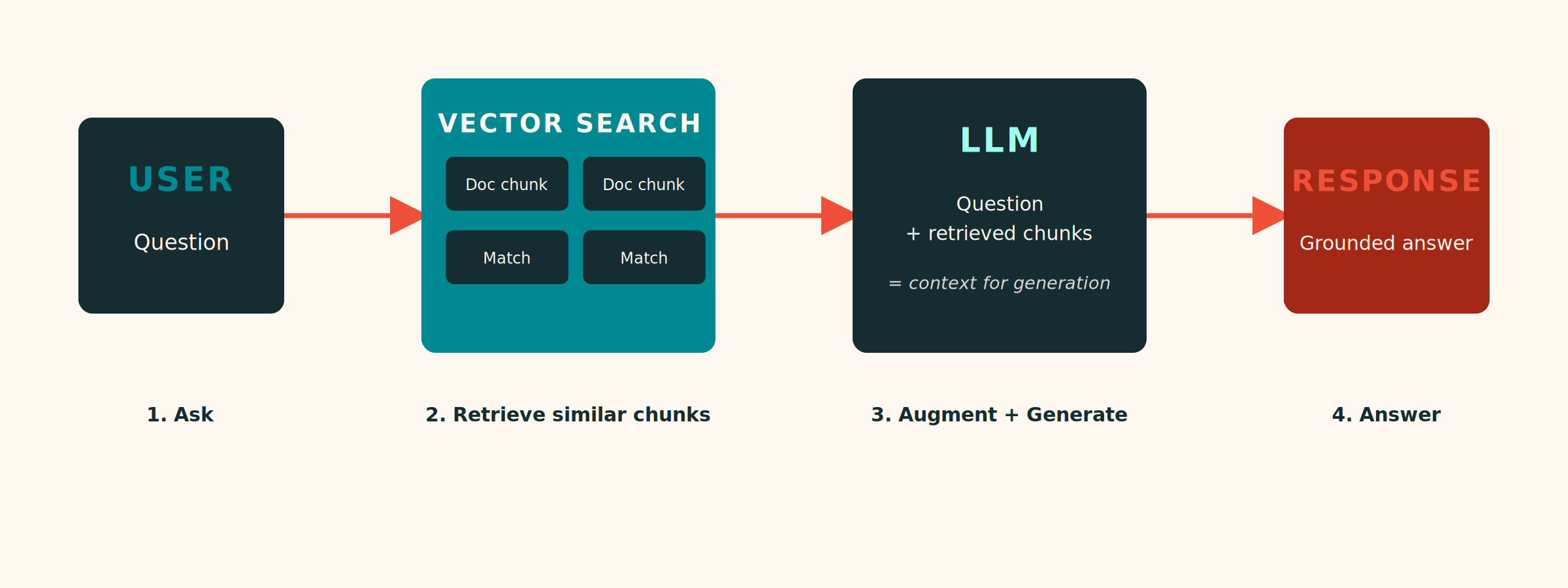
How Vector Similarity Search Works
The search step is where it gets interesting, and also where it starts to go wrong.
Most RAG systems find relevant documents using something called vector similarity search. Every piece of text, your question, and every chunk of every document in the database, gets converted into a long list of numbers (called a vector) that captures the meaning of that text in mathematical form. Words and phrases that mean similar things end up with similar numbers. When you ask a question, the system finds the document chunks whose vectors are closest to your question’s vector, and those become your “relevant” results.
If this sounds like a very sophisticated version of keyword search, that is because it essentially is, just one that understands synonyms and concepts rather than exact words. It works well when the answer lives inside a single document. It struggles when the answer requires connecting information across multiple sources, understanding when something was true, or resolving contradictions between different pieces of data.
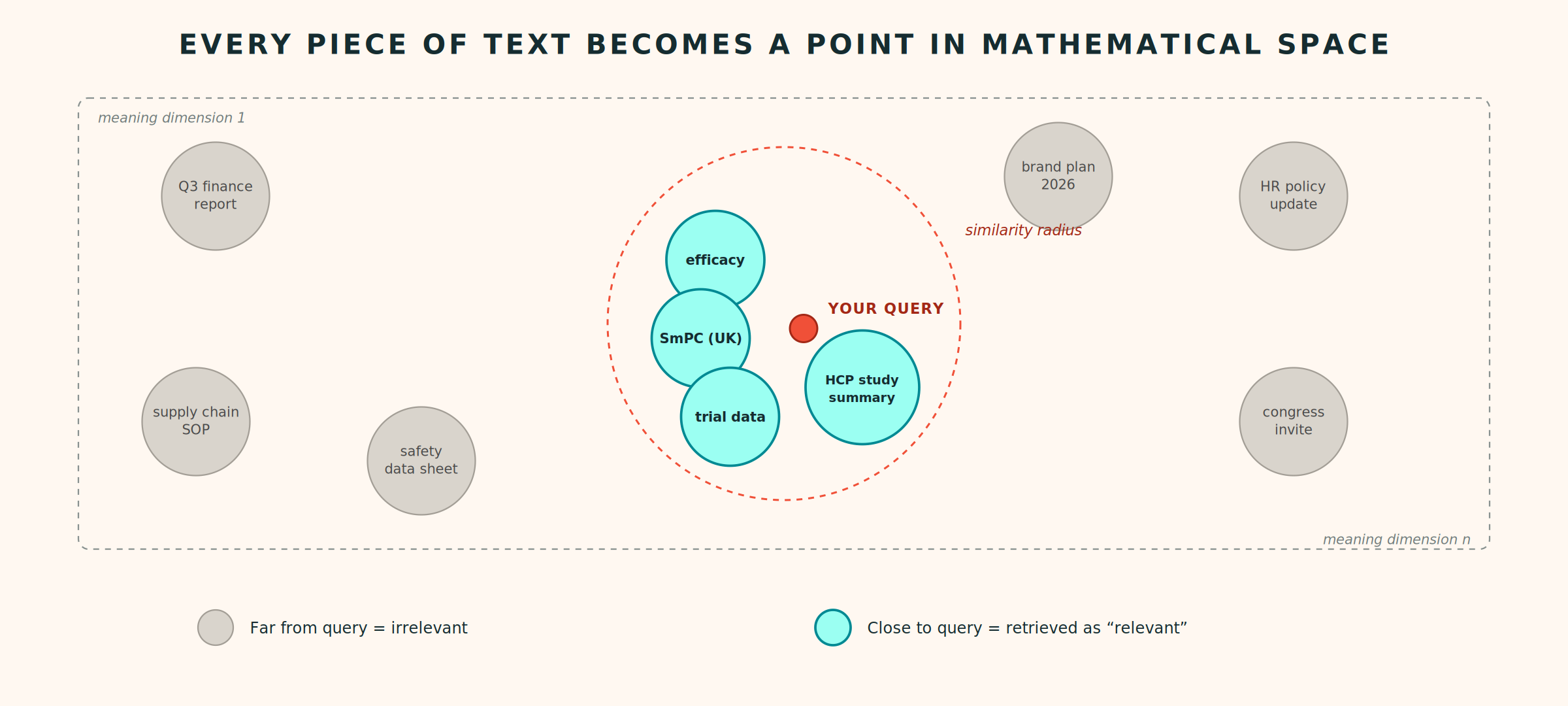
The questions that matter to brand, medical, and commercial teams almost always span multiple systems, time periods, and data types. The result is four recurring limitations that explain why AI tools in pharma consistently underdeliver despite the underlying technology being capable.
The Four Limitations of RAG
1. It Struggles to Connect the Dots
Standard RAG retrieves isolated chunks of text based on similarity, but it has no reliable mechanism to traverse the relationships between different pieces of information and build a synthesised answer. Microsoft Research tested this directly in their 2024 GraphRAG study (Edge et al., 2024). They took a dataset of thousands of news articles and asked both a standard RAG system and their graph-enhanced version to answer questions that required pulling together information from across the entire corpus. The standard RAG system consistently failed on these global questions because it could only retrieve individual text chunks matching the query. The graph-enhanced system substantially outperformed standard RAG: in head-to-head comparisons judged by an LLM evaluator, GraphRAG was selected as the more comprehensive answer 70-80% of the time. A subsequent independent evaluation noted that while GraphRAG consistently outperforms standard RAG, the magnitude of improvement is more moderate when evaluation biases are corrected (Han et al., 2025), and that GraphRAG’s advantage grows with query complexity.
What this looks like in pharma: A brand manager asks “Which HCP segments are most responsive to our efficacy-led messaging in the UK?” Answering this requires connecting content assets (tagged with “efficacy” messaging) to deployment records (filtered by UK market) to engagement data (broken down by HCP segment) to behavioural outcomes. That chain spans at least four systems, and no single document contains the answer. The RAG system will dutifully return whatever document chunks happen to mention efficacy, HCPs, and the UK in close proximity.
2. It Has No Sense of Time
Standard retrieval systems treat every piece of information as equally current. There is no awareness of when facts were true, when they changed, or when they expired. Rasmussen et al. (2025) at Zep AI built a system called Graphiti specifically to address this. Instead of storing facts as flat records, you store them with timestamps that track when each fact became true and when it stopped being true. Tested against existing benchmarks, this temporal awareness improved accuracy by up to 18.5% while reducing response time by 90%, with the strongest gains on questions that required understanding how information had changed over time.
What this looks like in pharma: Your system retrieves engagement data showing email open rates for a specific brand at 34%, which looks healthy. But that data is from Q2 last year, before a competitor launched in the same therapeutic area. Current open rates have dropped to 19%. The system has no way to know which figure is more relevant, because it treats everything it finds as equally valid. A time-blind system routinely serves yesterday’s truth as today’s insight, and you might not notice until a decision has already been made.
3. It Does Not Know That Your Systems Are Describing the Same Things
The system has no way of knowing that records in different systems are describing the same entity. A HCP in your CRM, a recipient in your mass email platform, and an attendee in your congress system might all be the same person, but to a retrieval system they are three unrelated data points with nothing connecting them.
What this looks like in pharma: Dr. X exists in your CRM as a cardiologist in Manchester, in your email platform as recipient ID 4472, and in your congress registration system as an attendee at ESC 2025. Ask an AI tool “What is Dr. X’s engagement history?” and it will return whatever fragments it can find in whichever system it searches first. It will never build a complete picture, because it does not know these records are related.
4. It Fills the Gaps with Guesswork
When an AI system lacks sufficient context to answer a question properly, it will often generate a plausible-sounding answer anyway — this is referred to as hallucination. The original RAG paper (Lewis et al., 2020) introduced the retrieval-augmented approach specifically to reduce this problem, but it did not solve it. Deloitte’s whitepaper on knowledge-enriched generative AI (2023) argues that structured knowledge graphs can reduce hallucination by providing verified, relationship-aware context. This is supported by the Lettria Hybrid GraphRAG benchmark (December 2024), which found that graph-enhanced retrieval achieved 80% accuracy versus 50.83% for vector-only RAG, with healthcare domains showing 85.7% versus 55.2%.
What this looks like in pharma: A commercial analytics team asks their AI tool to summarise a campaign’s content ROI. The system finds some spend figures and some engagement numbers in its retrieved chunks and generates a confident-sounding summary attributing a 3.2x return. The problem is that it pulled the spend from one campaign and the engagement from a different one with a similar name, because the system had no structural way to keep them separate.
These limitations are well documented, and the research consistently points to the same solution: structured knowledge. When RAG is backed by a context layer rather than a flat document store, the improvements are significant.
A note on modern RAG architectures. Agentic RAG systems use autonomous agents to plan multi-step retrieval; hybrid search combines lexical and semantic retrieval. These advances are genuine improvements. However, they address the retrieval problem without solving the structure problem. An agentic system that performs five retrieval steps across your document store is still searching text: it cannot traverse typed relationships between entities, distinguish when a fact was true, or resolve that records in different systems describe the same person. A related counter-argument is that expanding context windows will make retrieval unnecessary. But research consistently shows performance degrades well before stated limits — the “lost in the middle” phenomenon (Liu et al., 2024). More hay does not help you find the needle. It makes the haystack bigger.
The fundamental limitation across all four problems is the same: standard RAG gives your AI access to words, but not to meaning. It can find documents that look relevant. It cannot understand the relationships between the things those documents describe. For that, you need structure.
03 · The Three Missing Layers to Creating Structure
If RAG gives your AI the ability to find information, the three layers described here give it the ability to understand what it found. Each builds on the one before it, and together they turn a retrieval system into a reasoning system.
Layer 1: Rules
Rules are the explicit instructions that tell the system how to interpret what it finds. In pharma, this means encoding the logic that is currently trapped inside people’s heads: the regulatory constraints, the commercial environment, the therapeutic area knowledge, and the operational processes that shape how content gets created, approved, deployed, measured, and optimised.
Rules do several things at once. They enforce consistency by catching contradictions. They validate data quality by restricting what values a property can take. And they complement the pattern-matching that AI models are good at by providing a layer of logic that humans can actually inspect, verify, and trust.
What rules look like in practice:
- Rule 1: Channel classification. “If an asset is deployed via CRM with a send date, classify the channel as ‘Rep Triggered Email’. If the same asset is deployed via marketing automation to a segment list, classify it as ‘Mass Email’.” Why this matters: the same content asset performs completely differently depending on how it reaches the HCP. If the system cannot distinguish between them, downstream metrics will be structurally wrong.
- Rule 2: Market-specific indication gating. “If a content asset references an indication for a brand, only tag that indication to the asset in markets where it is approved. If the indication is pending or not approved in a given market, flag the asset and exclude it.” Why this matters: a content asset promoting one indication cannot be tagged and served in a market where that indication has not yet been approved.
A natural question is whether these rules could simply be encoded as instructions in an LLM prompt. They can, up to a point. But prompt-based rules are fragile: they cannot be versioned, audited, or tested independently of the model. When a prompt-based rule fails, it fails silently.
Layer 2: Classification
Classification is the bridge between your business language and the system’s understanding of your data. Every pharmaceutical company has its own vocabulary, its own way of describing therapeutic areas, brand strategies, customer segments, channel types, content categories, and campaign structures.
Classification typically covers three areas:
- Content Taxonomy — how assets are categorised by theme, key message, format, and strategic intent.
- Customer Data Model — how HCPs are described by specialty, prescribing behaviour, attitudinal segment, and HCP potential.
- Channel Data Layer — how touchpoints are classified across digital, field, and event-based interactions.
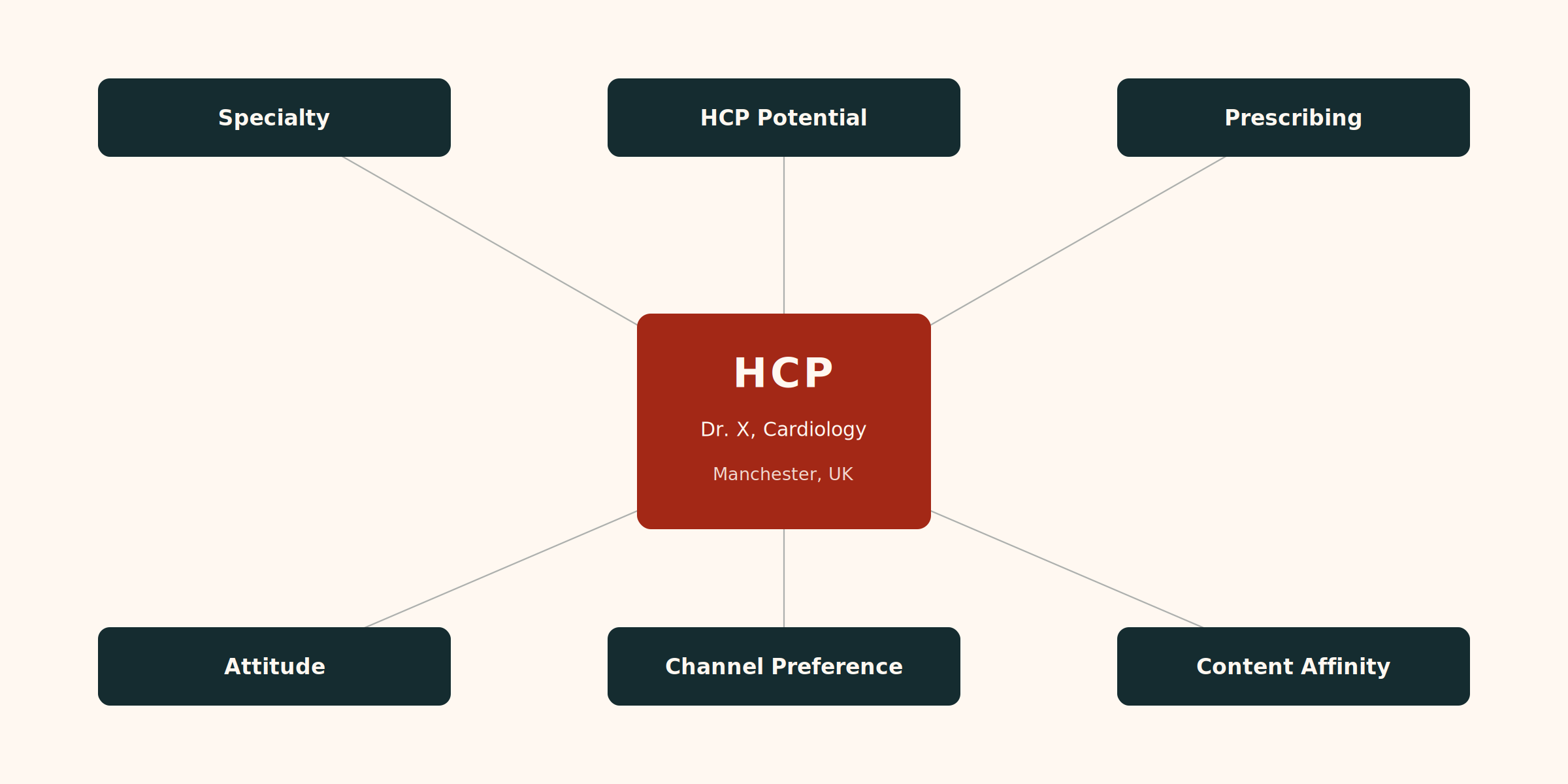
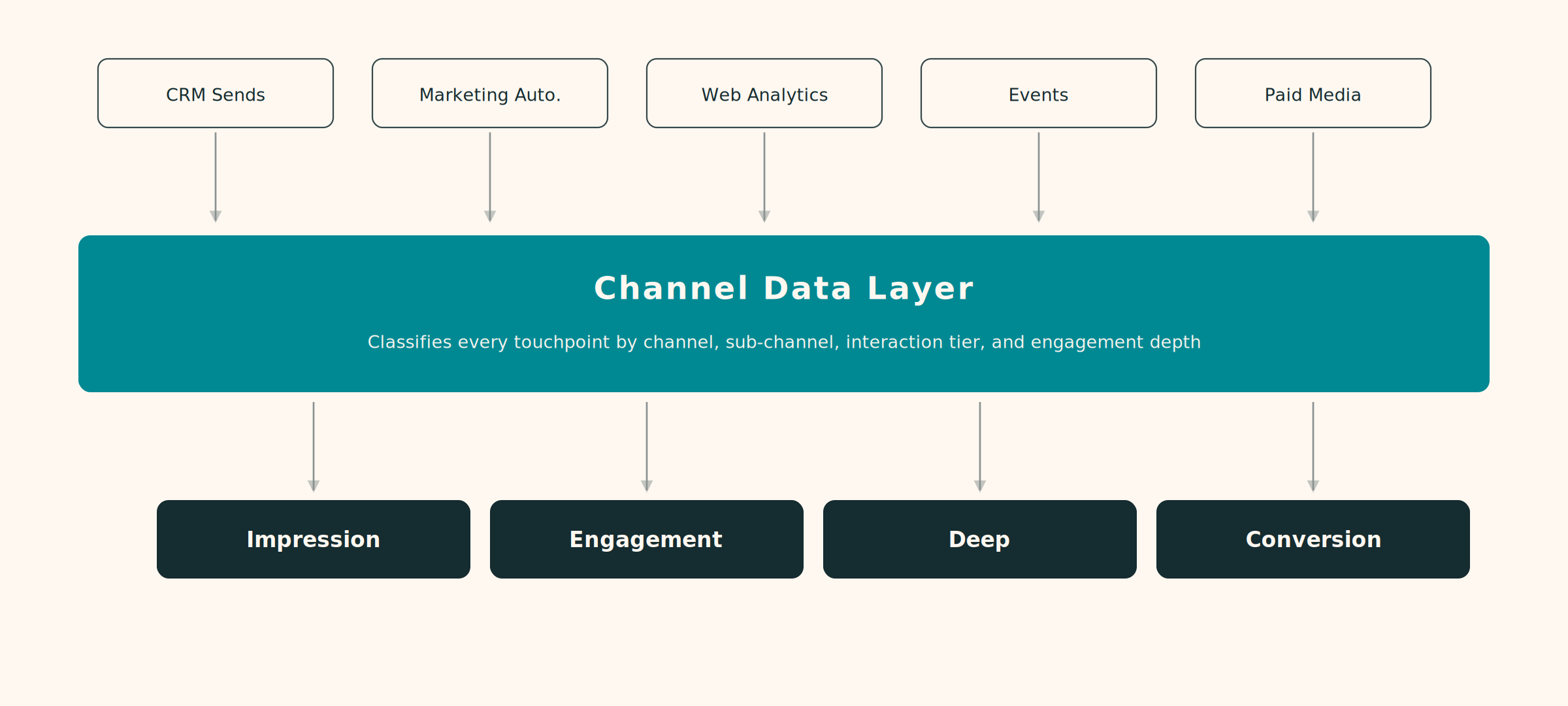
A single email asset might be classified as: Strategic Imperative = “Establish first-line positioning,” Therapeutic Area = Cardiovascular, Journey Phase = Consideration, Content Theme = Clinical Evidence, Key Message = “Superior reduction in MACE events,” Channel = Rep Triggered Email, Target Segment = High-Prescribing Cardiologists, HCP Potential = Decile 1-3. Without these labels applied consistently, the system cannot compare performance across campaigns or trace what actually drove the outcome.
Layer 3: Knowledge Graph
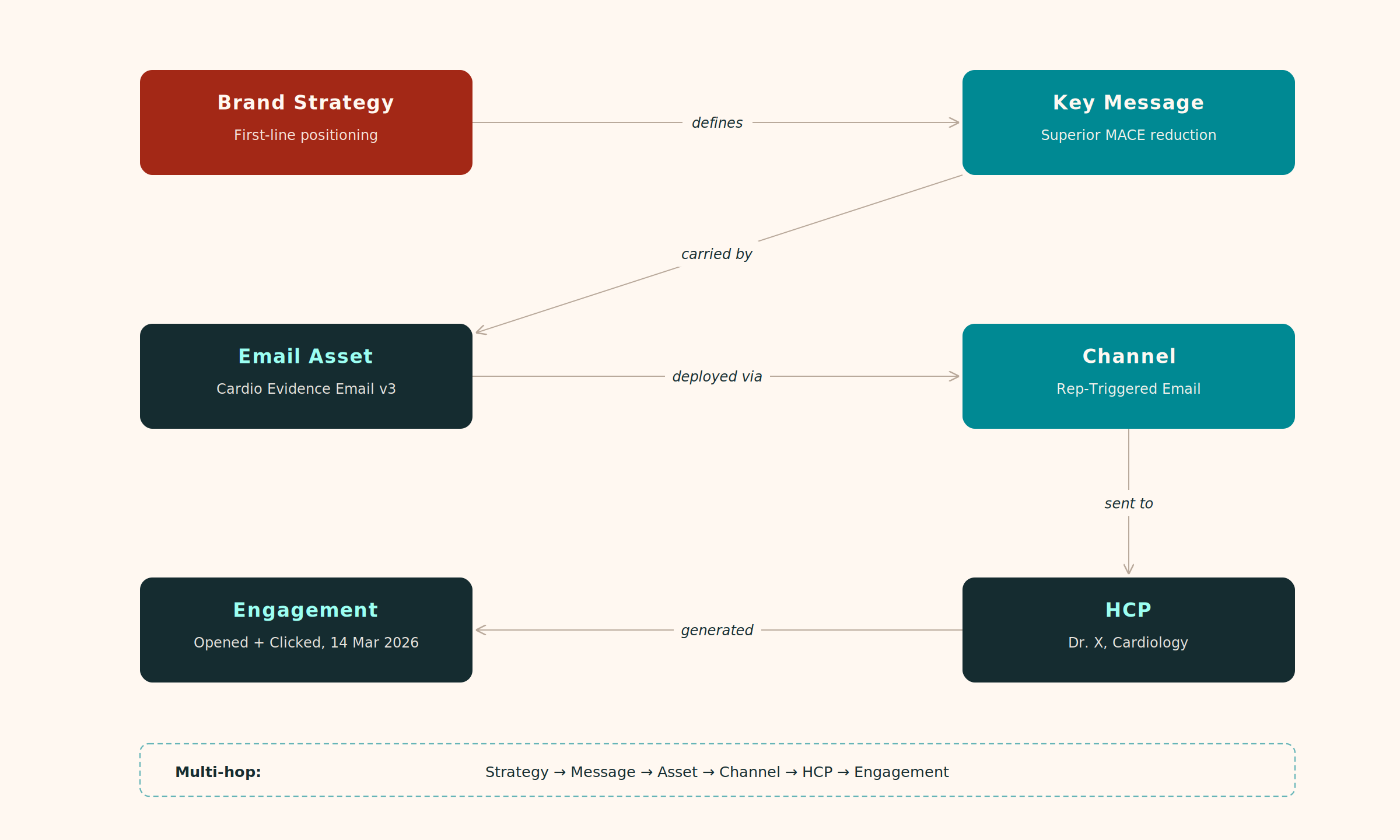
A knowledge graph is a way of representing data as a network of entities (things) and the relationships between them. Rather than storing information as isolated records, a knowledge graph makes the connections between those records explicit and traversable.
For pharmaceutical commercial teams, a knowledge graph connects a brand strategy to the key messages it defines, connects those key messages to the content assets that carry them, connects those assets to the channels they were deployed through, connects those channels to the HCPs who received them, and connects those HCPs to what they actually did next. Every connection is an explicit, typed relationship.
04 · Building a Context Layer
The three layers — rules, classification, and the knowledge graph — give your AI the ability to understand your data. A context layer is what you get when you bring all three together and enrich them with additional dimensions that reflect how information actually behaves in the real world.
A context layer encodes five dimensions alongside the data:
- Temporal context tracks when relationships existed, changed, or expired.
- Spatial context captures how geography affects relationships — market access in France differs from the UK.
- Semantic context defines the precise nature of relationships: whether one thing “supports” another, “contradicts” it, “depends on” it, or “replaced” it.
- Provenance tracks where information came from, giving teams the audit trail they need to validate insights.
- Confidence assigns certainty scores based on data quality and source reliability.
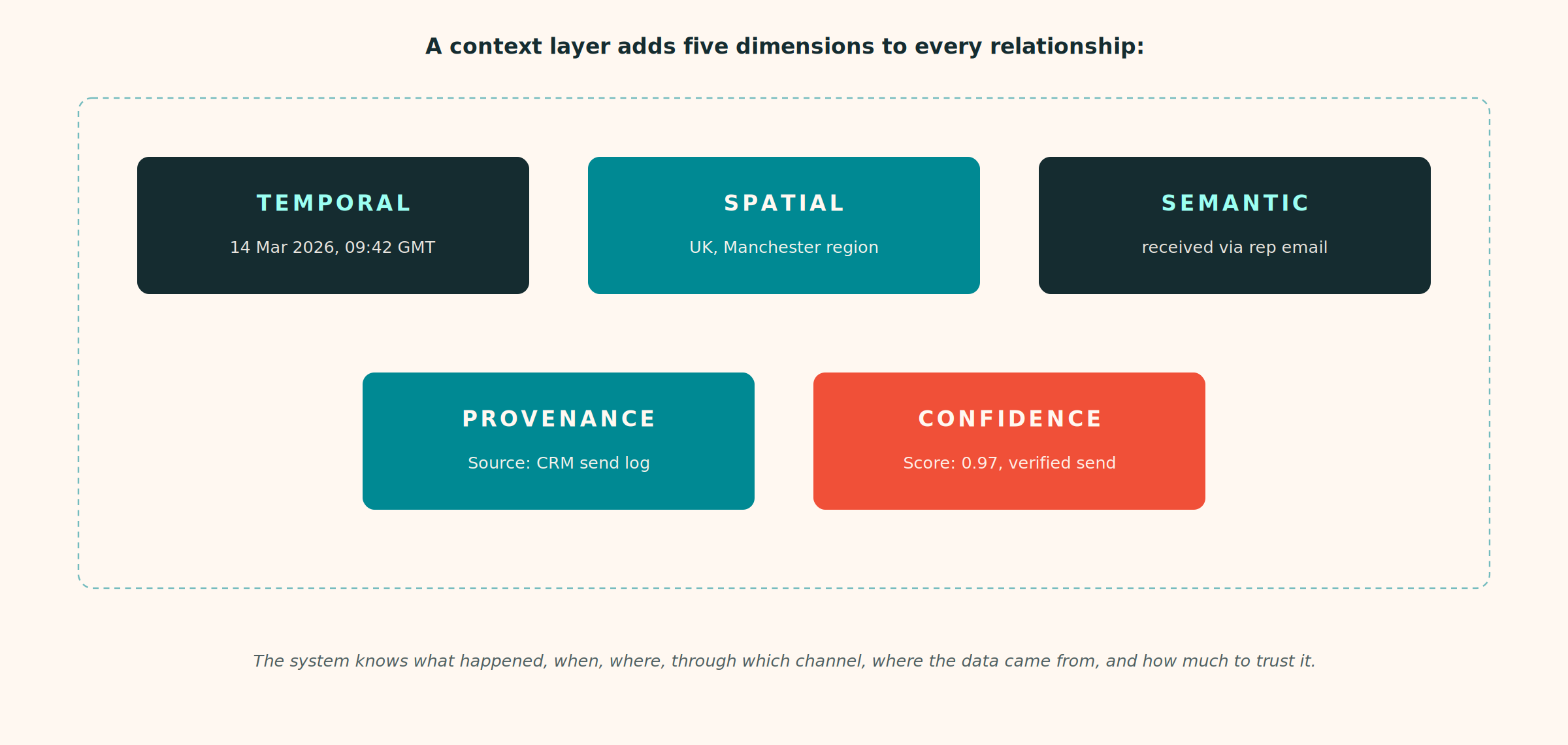
With all five dimensions in place, the context layer can tell you what happened, when it happened, where it applies, how the information got there, and how much you should trust it.
05 · How We Build It
Our approach has three stages, and they are sequential: each one depends on the one before it. The quality of your AI outputs is determined by the quality of these foundations.
Stage 1: Define Meaning, Rules, and Relationships. Before anything gets automated, we work with your teams to define meaning (the three classification structures), rules (the explicit business logic that governs classification), and relationships (how entities connect across strategy, content, channel, engagement, and customer), along with the five context dimensions that enrich every relationship.
Stage 2: Automate Tagging and Modelling. Once the rules and relationships are defined, we build the automation that applies them at scale. The tagging automation uses a combination of rule-based logic and LLM-powered classification, with human-in-the-loop validation for edge cases. Every tagging decision comes with a confidence score and a justification, which means the system is auditable, explainable, and compatible with human-in-the-loop validation.
Stage 3: Connect and Serve. With the context layer built and automation running, we connect it to your existing AI tools so your teams can query it using natural language. A brand director can ask a question in plain language and receive an answer grounded in the full connected context of their data, without needing to know which systems the data lives in.
What This Looks Like in Practice
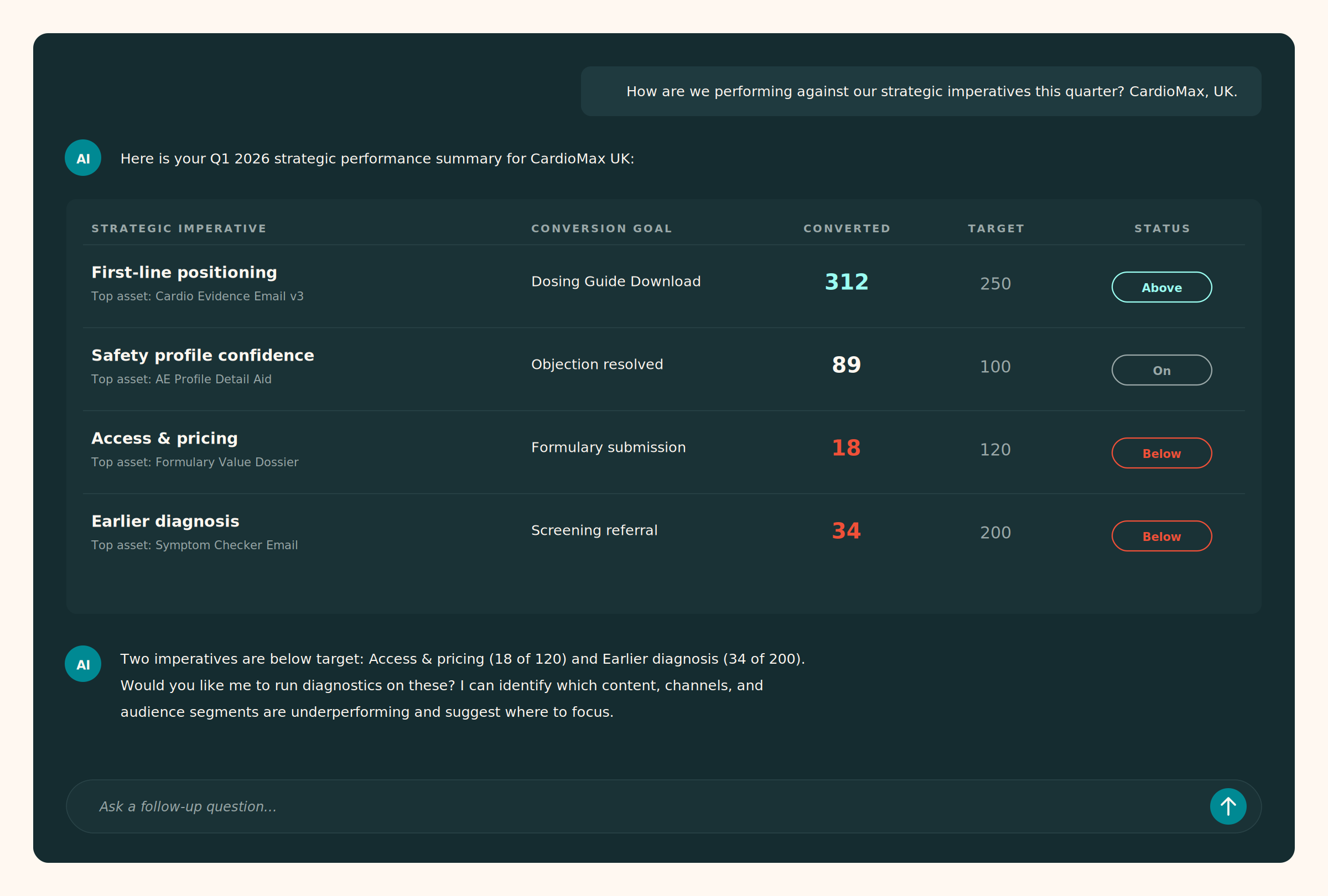
- Trace impact from plan to outcome. Every commercial decision can be followed from the brand plan through to the HCP response.
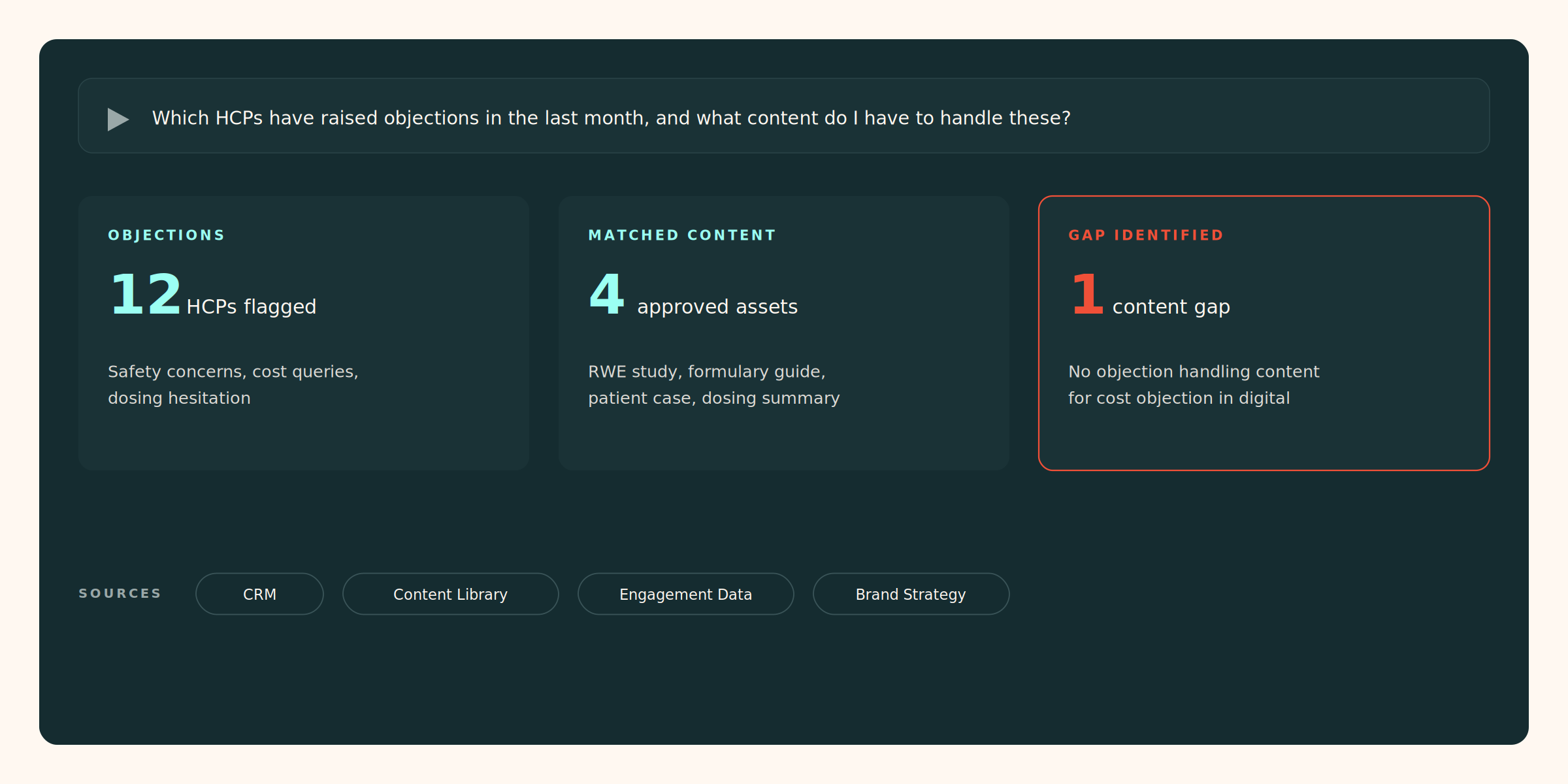
- Ask your data a question and get an answer that accounts for context. “Which HCPs have raised objections in the last month, and what content do I have to handle these?” — a query that spans CRM, content library, engagement data, and brand strategy, answered in seconds.
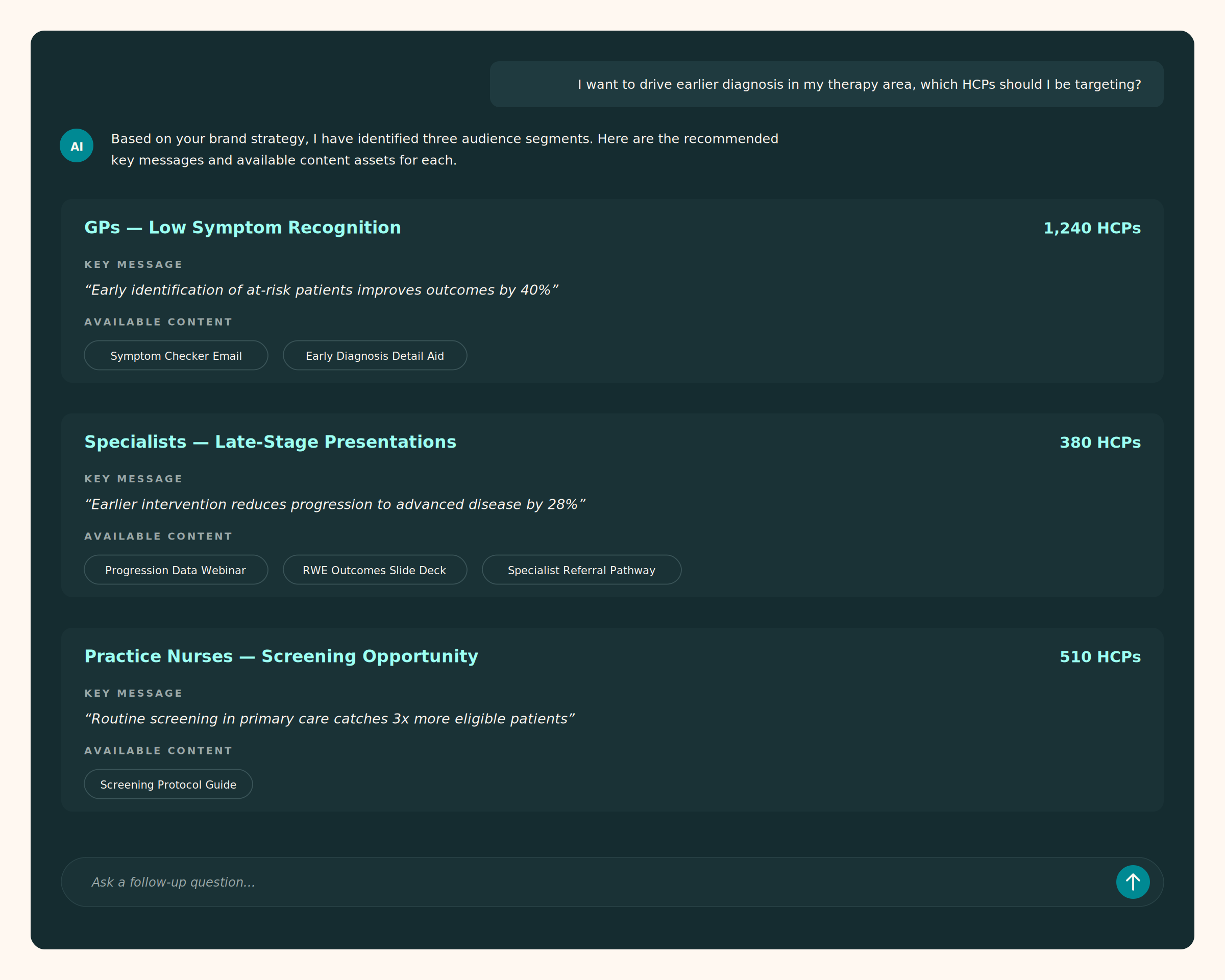
- Build engagement strategies grounded in what is actually working. “I want to drive earlier diagnosis in my therapy area, which HCPs should I be targeting?” — and the system builds audience segments based on prescribing behaviour, engagement history, and strategic fit.
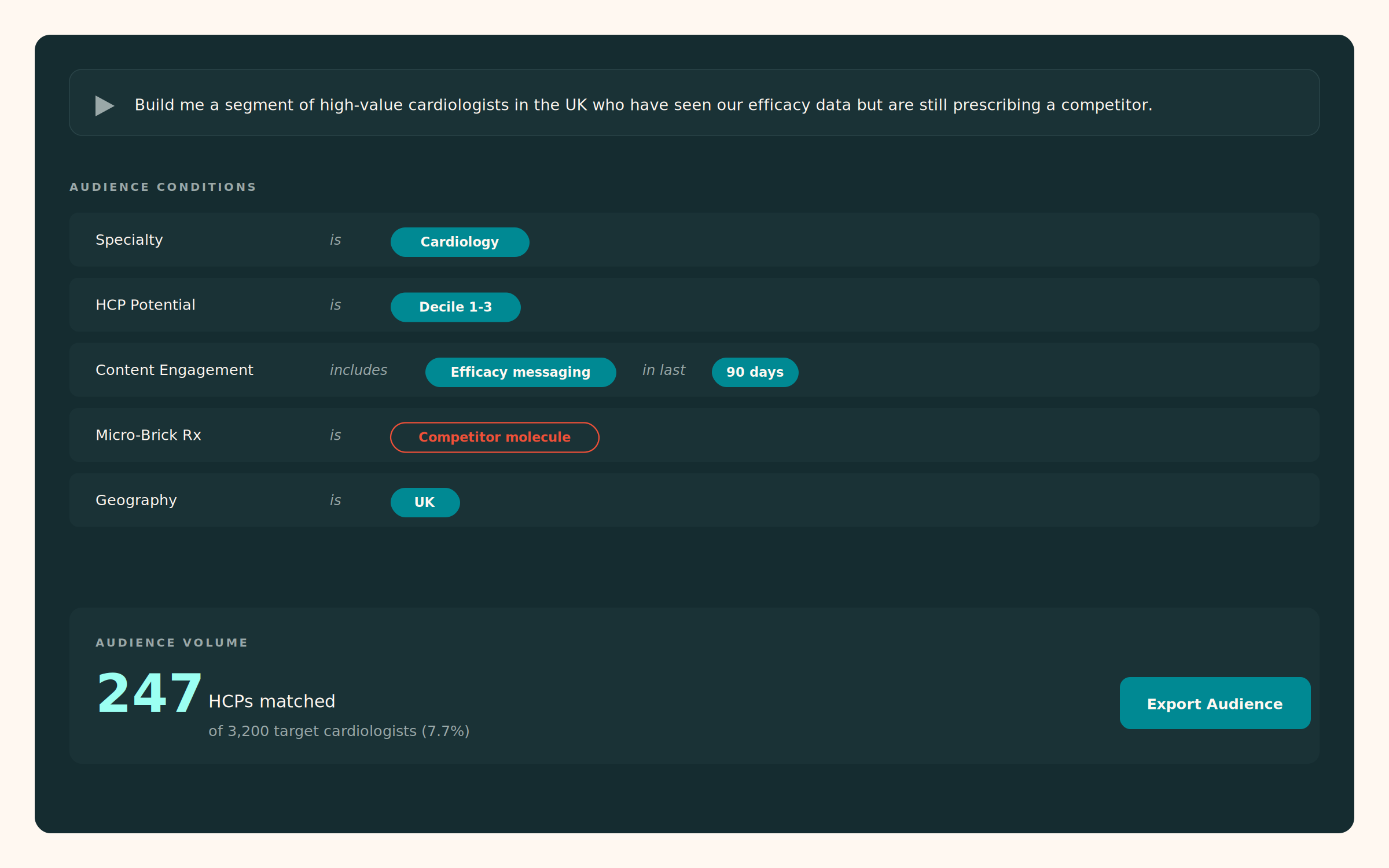
- Connect strategy to execution without the manual translation layer. Your teams describe what they need in plain English, and the system builds it from connected data.
06 · Getting Started
If you want to explore what a context layer would look like for your organisation, we would be happy to walk you through it: where your data is today, where the gaps are, and what it would take to close them.
Download the full whitepaper (PDF) — From Retrieval to Reasoning: Building a Data Foundation Fit for the Human-AI Partnership.
07 · Glossary of Key Terms
- RAG (Retrieval-Augmented Generation): A technique where an AI model searches a database of documents to find relevant information before generating a response.
- Knowledge Graph: A way of representing data as a network of entities connected by explicit, defined relationships.
- Context Layer / Context Graph: A knowledge graph enriched with five dimensions: temporal awareness, provenance, confidence scoring, spatial context, and semantic precision.
- Vector Similarity Search: The method most RAG systems use to find documents, converting text into vectors and finding the closest matches.
- GraphRAG: An approach from Microsoft Research that combines knowledge graphs with RAG.
- Taxonomy: A structured classification system — a shared dictionary of terms and categories.
- Multi-hop Reasoning: Answering a question by following a chain of relationships rather than finding one document.
- MCP (Model Context Protocol): A standard allowing AI tools to connect to external data sources.
- Hallucination: When an AI model generates plausible-sounding information that is factually wrong or unsupported.
- Provenance: The tracked origin of information.
- Content Intelligence Layer: Forge DC’s term for the automated infrastructure that continuously classifies, connects, and contextualises commercial data using domain-specific rules and taxonomies.
09 · References
- Lewis, P. et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS.
- Edge, D. et al. (2024). “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” Microsoft Research.
- Rasmussen, P. et al. (2025). “Zep: A Temporal Knowledge Graph Architecture for Agent Memory.” arXiv:2501.13956.
- Deloitte (2023). “Responsible Enterprise Decisions with Knowledge-enriched Generative AI.”
- Gartner (2025). Hype Cycle for Artificial Intelligence. Khandabattu, H. and Tamersoy, B., 11 June 2025.
- McKinsey (2024). “Generative AI in the pharmaceutical industry: Moving from hype to reality.”
- Han, H. et al. (2025). “How Significant Are the Real Performance Gains? An Unbiased Evaluation Framework for GraphRAG.” arXiv:2506.06331.
- Lettria (2024). Hybrid GraphRAG Benchmark. Reported via AWS ML Blog, December 2024.
- Paulsen, N. (2026). “Context Is What You Need: The Maximum Effective Context Window for Real World Applications.” OAJAIML, 6(1), 4853-4878.
- Liu, N. et al. (2024). “Lost in the Middle: How Language Models Use Long Contexts.” TACL, 12, 157-173.